

「こんばんは、俵孝太郎です」、もといFURUです(ネタが古い!)。
突然ですが、ここ最近、noteやxなどで、「AIまんがで副業!月に〇〇万円稼げました!」という投稿をよく目にしませんか?
いわゆる、生成AIまんがのトップランナーさんたちは、肝心の漫画も描かず(生成せず)、情報商材の販売や、高額セミナーの開催に余念がありません。
まさに地獄の様相を呈しています。正直羨ましいので、あやかりたい所ジョージさんですhi。
で、皆さんは「AIでマンガを作ろう」と思ったとき、どこまでAIに任せていますか?
プロンプトを一生懸命考え、何度もガチャを回し、Photoshopで修正し……。画像編集ソフトでまんがのコマを割り、その中に出来た画像を流し込む…。
このような状況を打破するために、私たちは「Nano Banana Pro Powered Super AI 4-koma System」を開発しました。
正直、「これ、普通に描いたほうが早くね?」と思ったことはありませんか?
私もそうでした。正直、アホらしくてやってられませんでした。
それゆえ、ちょっとAIをかじった程度の髪壊死、もとい神絵師と呼ばれる人たちが、「所詮、AIなんて、漫画のネームすら作れないダメダメなシステムさ、フフフン♡」と、鼻の下を伸ばしていた、もとい、鼻を高くしている様子を苦々しく思っていた日々でした。
ワタクシは、かねてよりマンガ界の、画力によるヒエラルキーが大嫌いでしたので、「いつか見返してやる」と、心に固く誓ったのでした(←誰に向かって?)。
しかし、よくよく考えたら馬鹿にされたのは、AIであって、私ではありま♨せんでした。
そもそも私自身は絵師の世界からは、馬鹿にされる以前に、奴らの視界に入ってすらいなかったわけです。(´・ω・`)ショボーン
という訳で、そんな状況を打破マイロードするべく、新たに生成AIまんがシステムを作ろうと思ったわけですが、その時点で、いわゆる、生成AIまんがのトップランナーが荒稼ぎしている(←しつこい)、その商材の中には、生成AIまんがアプリもありました。
「お、すでにあるじゃん」と思って値段を見て見ると、お値段以上の「数万円」。
その中身はというと概ね……。ようするに、まんがの基本設計書として、AIが読みやすい書式である「YAML」や「json」形式のファイルのテンプレートに、自分でコマの内容やセリフを描き込みましょうね、という基本設計のものでした。
いわゆる生成AIの場合、日本語で「4コマ漫画を作って!」としてザックリとした指示を出しただけでは、コマのサイズがバラバラになってしまったり、コマから絵がはみ出したり、キャラクターの顔が全コマ違う人物になってしまうので、あらかじめAIが分かりやすい、AI用の言語(そのものではないが、読みやすいもの)を、人間様がシコシコAI様に合わせてお勉強して記述しましょうねー、みたいな感じで、そのノウハウを売っていたワケです。
「ふざけんなー!」
こんな銭ゲバゲバ60分な連中に、これからAIまんが家を夢見て目指そうとする人々が搾取されるのは、酷すぎて見ていられません。
そこで、私がこれから取り組む「生成AIまんが作成ツール」は、絶っっ対、オープンライセンスにしてやるぜと、固く心に決めたのでありました。
商業主義から背を向け、人類の発展と文化の向上に寄与し、金儲け主義に反旗を翻す。我ながらカックイー。だから金欠なのか。
さて、折角「生成AIまんがシステム」を作るにあたっては、これまでのような、単に手書き漫画の制作過程の一部を、AIに置き換えるというだけの仕組みでは、あまりに芸が無い。というか既にそういったツールは結構沢山あります。
そこで、今回は発想を根本から変えてみました。
目指したのは「自動化(Automation)」ではありません。その先にある「無人化(Unmanned)」です。
これは、記事執筆時、まだ誰もやっていない手法です。現時点で世界初だとAIが申しておりました(2026/01/31)。
そこで今回、ルサンチマンの筆者が、
”人間がクリエイティブな判断(ネタ出し、構図、演出)から完全に降り、AI自身が「監督」として全てを決定する。 そんな狂気の実験的Webアプリケーション「Nano Banana Pro Powerd Super FURU AI 4-koma System」”
を開発しました。 我ながら乙牌、もといオーパーツを作ってしまったので、少々恐れおののいています。
今回はその技術的裏側を、余すところなく「深掘り解説」していきます。
1. なぜ「無人化」なのか? ~AIを道具から監督へ~

従来のAI画像生成は、あくまで「人間の道具」でした。
人間が「右を向いて」と言えば右を向き、「青い服を着て」と言えば着る。
しかし、これでは人間自身の想像力の範囲を出られませんし、AIは言われたことしかやりません。その結果、スカスカの絵とストーリーの、ゴミのような漫画が量産されます。それじゃ意味がありません。
本プロジェクトのコンセプトは「人間は、どこまで制作から降りられるのか?」です。
私が開発した「Nano Banana Pro Powerd Super FURU AI 4-koma System」では、スタートボタンを一回押すだけで、以下のプロセスが全自動・無人で進行します。
- 【眼】キャラクター解析: アップロードされた設定画をAIが視覚的に解析し、その特徴(髪型、アクセサリー、性格)を数値化して記憶する。
- 【脳】ネタの自律収集: その日の「最新ニュース」や「トレンド」を勝手に検索し、それを風刺した4コマ漫画のプロットを書き上げる。
- 【手】超演出プロトコル: 独自の「Super FURU Manga Protocol」に基づき、コマ割り、カメラアングル、画風を物理的に強制固定して描画する。
これにより、人間が寝ている間に、AIが勝手に社会情勢を憂い、自動的にマンガを描いて発表してくれるシステムが完成しました。
※一応試用版は、計算過程が分かるように、進捗ステップ毎にクリックする仕様にしています。中に人が入ってるんじゃねーかと思われるのもイヤなので。
2. 技術スタック:React 19 × Gemini 2.0 Thinking

まず、このシステムの心臓部について解説します。
- Frontend: React 19 + Vite 7
- Design: Tailwind CSS (Glassmorphism UI)
- Logic (Brain): Google Gemini API (gemini-2.0-flash-thinking-exp)
- Renderer (Hand): Google Imagen 3
特筆すべきは、論理エンジンに「Gemini 2.0 Flash Thinking」を採用している点です。
従来のLLM(大規模言語モデル)は、即座に答えを出そうとして浅い回答になりがちでした。しかしThinkingモデルは、プロンプトを生成する前に「思考プロセス」を挟みます。
実際のAPIコール部分のコード(src/lib/gemini.js)を見てみましょう。あえて実験的な thinking-exp モデルを優先的に呼び出すように設計しています。
// src/lib/gemini.js
const MODEL_IDS = [
"gemini-2.0-flash-thinking-exp-01-21", // 最新のThinkingモデルを最優先
"gemini-2.0-flash-thinking-exp",
"gemini-2.0-flash",
// ...
];
export const callThinkingGemini = async (prompt, images = null, systemInstruction = null) => {
// ...
// Thinkingモデル特有の「思考プロセス(thought)」を取得する処理
const responseParts = candidate.content?.parts || [];
let thought = "";
responseParts.forEach(part => {
if (part.thought) thought += part.thought;
});
return {
text: finalOutput,
thought: thought || "Standard processing complete..."
};
};「このコマはオチだから、アングルをもっと極端にしたほうがいいな…」 「キャラAはツッコミ役だから、ここでは呆れ顔にすべきだ…」
このようにAIが「熟考」してから描画命令を出すため、演出の密度が劇的に向上しました。
ようするに、人間があれこれ画面全体の構成や、ストーリーの構造を考えなくても、
ざっくり「こんな感じでテキトーに考えて」という指示を出せば、可能な限り、「このざっくりした指示に、キッチリまんがとして整合性つけるとしたら、こんなストーリーでこんな画面構成になるよねー」と言った内容を、強力なパラメーターの値付けにより、徹底的に画面構成を埋めまくり情報量を増やしまくることで実現する設計にしました。
これで少なくとも、画面スカスカのまんがにはなりません。画面が五月蠅すぎるという批判はありますが、聞かなかったことにします。
情報量を減らしたい場合は、再生成指示を出してください。
3. 【眼】の技術:キャラクター同一性の物理的強制

AIマンガ最大の課題、それは「キャラが安定しない(同一性の崩壊)」です。 1コマ目ではショートヘアだったのに、3コマ目ではロングヘアになっている……なんてことは日常茶飯事です。
凡庸な生成AIまんがシステムは、全コマに対して、YAMLやjson形式で、ユーザーに手書きでキャラクター情報を書かせます。折角のAIなのに、もうアホかと。それをAIにやらせないでどうする!
そこで今回、私が実装したのが、「Weighted Immutable Prompts(重み付き不変プロンプト)」技術です。LoRA不要の優れものです。
システムはまず、ユーザーがアップロードしたキャラクター設定画(三面図など)を「Gemini Vision」で解析します。 ここで重要なのは、単に「赤い髪の女の子」と認識させるだけでは不十分だということです。
実際のコード(App.jsx内の解析ロジック)では、以下のようにAIに「幻覚」を見せないための厳しいルールを課しています。
// src/App.jsx
const analyzeCharacters = async (imageArray) => {
// ...
const prompt = `
/* SYSTEM: ABSOLUTE CONTEXT RESET. FORGET ALL PREVIOUS CHARACTERS. */
/* TARGET: Analyze ONLY the currently uploaded image. Do not recall past sessions. */
あなたはプロの漫画家兼キャラクターデザイナー(解析特化)です。
以下の「絶対厳守ルール」に従い、現在の画像のみを解析してください。
【0. 画像スタイル判定 (Style Detection)】
・最初に必ず「STYLE_TAG: MONOCHROME」または「STYLE_TAG: COLOR」と出力せよ。
【2. 特徴の超精密分解 (High-Fidelity Decomposition)】
A. **【性別と年齢 (Gender & Age)】**:
- 最重要: 性別を間違えるな。ショートカットの女性を男性と誤認するな。
- 女性なら (female:1.6), (girl:1.4)、男性なら (male:1.6), (boy:1.4) を必ず付与せよ。
B. **髪の完全構造化 (Hair Structure)**:
- **【ハゲ/坊主 (Bald/Buzz)】**:
- 髪が無い場合は「Bald」と判定せよ。
- **【色 (Tone/Color)】**:
- 白黒の場合: 「ベタ(黒)→Black」「トーン(灰)→Brown/Dirty Blonde」...
`;
// ...
};AIは画像をピクセルレベルでスキャンし、例として、以下のような「重み付きタグ」を生成します。
(chin-length bob:1.5)(orange brown hair:1.4)(blunt bangs:1.1)
この「 :1.5 」や 「:1.4 」という数値が重要です。これは画像生成AIに対し「この特徴だけは絶対に死守しろ」と命令する強度パラメータです。
これを全コマのプロンプトに強制的に埋め込むことで、AIがどれだけ暴走しようとも、キャラクターの造形だけは「物理的に」固定される仕組みです。
※この値は現時点での経験則ですので、モデルがアップデートしたり諸環境が変わった場合は、また調整が必要かもしれません。
ちなみに、以下のキャラクターシートを、本システムに読み込ませると……。
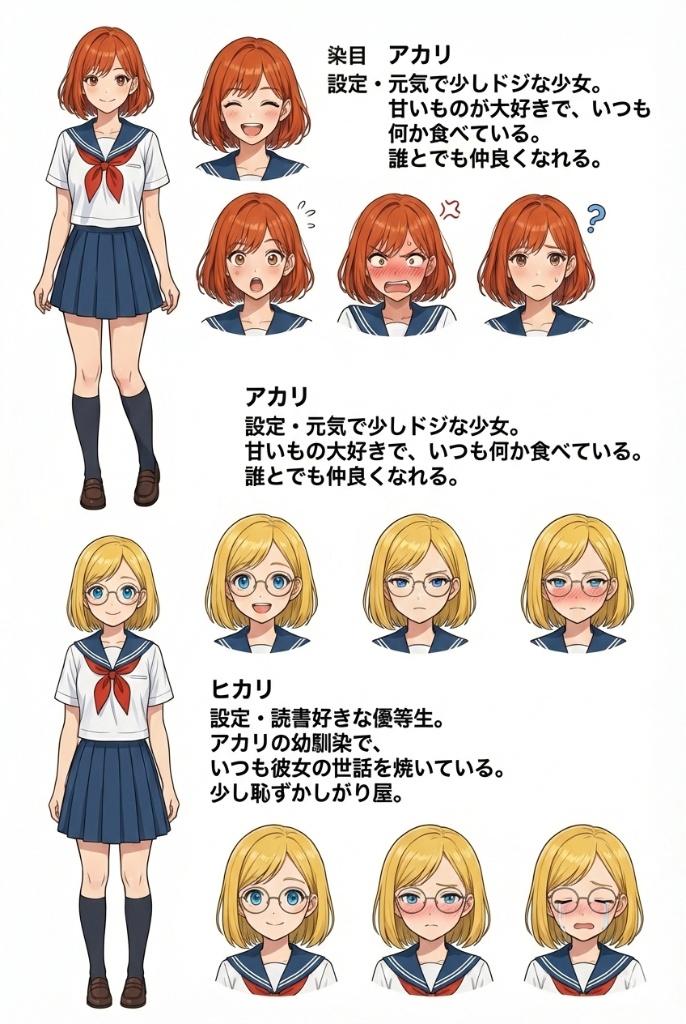
このようなプロンプトを吐いてくれます。まあここまで分析してくれれば、キャラクターとしても本望でしょう。
```text
STYLE_TAG: COLOR
```
## 1. アカリ
| カテゴリ | 特徴の詳細(日本語) | 画像生成AI用 重み付きタグ (Weighted Immutable Prompts) |
| :--- | :--- | :--- |
| **基本(Base)** | 性別: 女性<br>年齢: ティーンエイジャー | **[WEIGHTS]: (female:1.6), (teenager:1.2)** |
| **髪(Hair)** | 色: オレンジ<br>構造: 丸みのあるショートヘア<br>前髪: パート<br>結び: なし | **[WEIGHTS]: (short orange hair:1.4), (parted bangs:1.2)** |
| **顔(Face)** | 目: 茶色<br>肌: 普通<br>髭: 無し<br>眼鏡: 無し | **[WEIGHTS]: (brown eyes:1.2), (normal skin:1.0)** |
| **服装(Outfit)** | セーラー服 | **[WEIGHTS]: (sailor uniform:1.2)** |
| **性格(Mind)** | **[OCR抽出]**: 元気で少しドジな少女。甘いものが大好きで、いつも何か食べている。誰とでも仲良くなれる。 | - |
## 2. ヒカリ
| カテゴリ | 特徴の詳細(日本語) | 画像生成AI用 重み付きタグ (Weighted Immutable Prompts) |
| :--- | :--- | :--- |
| **基本(Base)** | 性別: 女性<br>年齢: ティーンエイジャー | **[WEIGHTS]: (female:1.6), (teenager:1.2)** |
| **髪(Hair)** | 色: 金髪<br>構造: ボブ<br>前髪: パート | **[WEIGHTS]: (blonde bob hair:1.4), (parted bangs:1.2)** |
| **顔(Face)** | 目: 青色<br>肌: 普通<br>髭: 無し<br>眼鏡: 有り (丸眼鏡) | **[WEIGHTS]: (blue eyes:1.2), (glasses:1.2), (round glasses:1.4)** |
| **服装(Outfit)** | セーラー服 | **[WEIGHTS]: (sailor uniform:1.2)** |
| **性格(Mind)** | **[OCR抽出]**: 読書好きな優等生。アカリの幼馴染で、いつも彼女の世話を焼いている。少し恥ずかしがり屋。 | - |
```(後編へ続く)


